Is a vuln without a useful exploit still a vuln?
Here’s a case where a page has one of the simplest types of XSS vulns: A server echoes the querystring verbatim in the HTTP response. The payload shows up inside an HTML comment labeled “Request Query String”. The site’s developers claim the comment prevents XSS because browsers will not execute the JavaScript, as below:
<!-- _not gonna' happen_ -->
One exploit technique would be to terminate the comment opener with “ –>” (space dash dash >). Use netcat to make the raw HTTP request (for some reason, though likely related to the space, the server doubles the payload1):
$ echo -e "GET /nexistepas.cgi? --> HTTP/1.0\r\nHost: vuln.site\r\n" | nc vuln.site 80 | tee response.html
...
<!-- === Request URI: /abc/def/error/404.jsp -->
<!-- === Request Query String: pageType=error&emptyPos=100&isInSecureMode=false& --> --> -->
<!-- === Include URI: /abc/def/cmsTemplates/def_headerInclude_1_v3.jsp -->
...
You can confirm this works by viewing the HTML source in Mozilla to see its syntax highlighting pick up the tags (yes, you could just as easily pop an alert window).
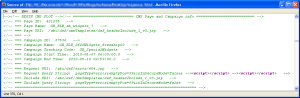
The server is clearly vulnerable to XSS because it renders the exact payload. The HTML comments were a poor countermeasure because they could be easily closed by including a few extra characters in the payload. This also shows why I prefer the term HTML injection since it describes the underlying effect more comprehensively.
However, there’s a major problem of effective exploitability: The attack uses illegal HTTP syntax.2 Though the payload works when sent with netcat, a browser applies URL encoding to the payload’s important characters, thereby rendering the it ineffective because the payload loses the literal characters necessary to modify the HTML:
https://vuln.site/nexistepas.cgi? -->
...
<!-- === Request URI: /abc/def/error/404.jsp -->
<!-- === Request Query String: pageType=error&emptyPos=100&isInSecureMode=false&%20--%3e%3cscript%3e%3c/script%3e -->
<!-- === Include URI: /abc/def/cmsTemplates/def_headerInclude_1_v3.jsp -->
...
I tried Mozilla’s XMLHttpRequest object to see if it might subvert the encoding issue, but didn’t have any luck. Browsers are smart enough to apply URL encoding for all requests, thus defeating this possible trick:
var req = new XMLHttpRequest();
req.open('GET', 'https://vuln.site/nexistepas.cgi? --><scri' + 'pt></s' + 'cript>', false);
req.send(null);
...
The developers are correct to claim that HTML comments prevent <script> tags from being executed, but that has nothing to do with protecting this web site. It’s like saying you can escape Daleks by using the stairs; they’ll just level the building.

The page’s only protection comes from the fact that browsers will always encode the space character. If the page were to decode percent-encoded characters or there was a way to make the raw request with a space, then the page would be trivially exploited. The real solution for this vuln is to apply HTML encoding or percent encoding to the querystring when it’s written to the page.
Set aside whether the vuln is exploitable or not. The 404 message in this situation clearly has a bug. Bugs should be fixed.
The time spent arguing over risks, threats, and feasibility far outweighs the time required to create a patch. If the effort of pushing out a few lines of code cripples your development process, then it’s probably a better idea to put more effort into figuring out why the process is broken.
Notice that I didn’t mention the timeline for the patch. The release cycle might require a few days or a few weeks to validate the change. On the other hand, if minor changes cause panic about uptime and require months to test and apply, then you don’t have a good development process – and that’s something far more hazardous to the app’s long-term security.
-
Weird behavior like this is always interesting. Why would the querystring be repeated? What implications does this have for other types of attacks? ↩
-
Section 5.1 of RFC 2616 specifies the format of a request line must be as follows (SP indicates whitespace characters):
Request-Line = Method SP Request-URI SP HTTP-Version CRLFIncluding spurious space characters within the request line might elicit errors from the web server and is a worthy test case, but you’ll be hard-pressed to convince a standards-conformant browser to include a space in the URI. ↩