Posts (page 1 of 43)
-
ASW Recap for March 2025 Apr 4, 2025
March meandered through C code, mused about secure design, marked a new top ten list, made space for machines, and finally descended into a bit of madness. And every single moment was fun!

Keeping Curl Successful and Secure Over the Decades (ep. 320)
Our month kicked off with curl’s continuous curator, Daniel Stenberg, explaining the project’s approach to appsec. It has had to deal with bad bug bounty reports from LLMs and inflated CVSS scores from CVEs.
It’s also had positive experiences and established itself as a positive model for security, which is especially impressive given its steadfast commitment to C. About 40% of its security bugs are attributable to a memory safety issue. But the library supports a massive set of protocols, many of which date back to ancient or ambiguous RFCs. Dealing with protocol state machines and parsing complex data introduces a whole set of security challenges and the potential for logic flaws.
Curl’s longevity is commendable. It’s been going for over 27 years now. The project fosters a wide community of contributors, maintains a consistent standard of quality (of which security is just one part), and has created such a fundamentally useful tool that it’s no surprise to find it on billions of devices worldwide – or worlds-wide if you include Mars!
CISA’s Secure by Design Principles, Pledge, and Progress (ep. 321)
CISA has been pushing for more software to be secure by design and secure by default. Jack Cable shared how CISA chose to frame their Secure by Design principles and encourage businesses to improve their software quality.
It’s not like vuln classes and countermeasures are unknown. Phrack 54 covered SQL injection vulns in 1998. All the major databases supported prepared statements by 2004. Yet in 2025 we already have a few hundred CVEs for SQL injection (and XSS and a few other usual suspects).
But one of the important qualifiers for “easy” fixes is that they have to be “easy to implement and deploy”. Not everyone has Google’s budget for appsec.
Redlining the Smart Contract Top 10 (ep. 322)
There’s no better place to discover the impact of logic flaws than in the cryptocurrency space, where every token is its own self-funding bug bounty and every contract is a gamble in code correctness.
Shashank went into the details of the 2025 edition of the Smart Contract Top 10, how it has changed over the past two years, and how security improvements in Solidity might change it again (for the better!) in another two years.
I appreciate this particular Top 10 list because it’s not repetitive of all the others and its entries are domain-specific to crypto. Shashank provided lots of technical background and real examples across familiar appsec flaws like integer overflows and reentrancy problems. More importantly, he talked about the logic problems behind oracle manipulations and flash loan attacks.
Crypto is rife with rug pulls, scams, and questionable tokens. But it’s also a great learning space for classes of attacks that aren’t memory safety flaws or the dusty XSS and SQL injection of the web.
Thanks again to Shashank for making this topic accessible and engaging!
Finding a Use for GenAI in Appsec (ep. 323)
Sure, LLMs are helping devs write code, but is it secure code? How are LLMs helping appsec teams?
Keith Hoodlet returned to talk about those questions and put the capabilities of LLMs into perspective.
There are notable areas where LLMs prove to be helpful assistants, like having better contextual seeds to craft a fuzzing corpus. There are areas where LLMs could quite directly prove their value in bug bounty hunting. But there are also areas where we’ve been underwhelmed (so far!) by the generic LLM responses to threat modeling and security reviews.
We also discussed the importance of reading beyond the headlines of research papers in order to avoid hype and better understand what’s improving – and what’s not – in terms of code generation and security capabilities.
I always enjoy talking with Keith. Regardless of how much of a future we’ll have with appsec toasters, he’ll always be a human I turn to for insights in this area.
Avoiding Appsec’s Worst Practices (ep. 324)
We entertained some foolish notions about the worst ways to approach appsec. But out of that chaos emerged some debate about tracking tons of vulns, using LLMs, and what secure design means.
Does vibe coding need vibe appsec? Do those words mean anything? Why does infosec love bad metaphors? What’s the best direction to shift? What are we even shifting in the first place?
Shout out to Jackie McGuire and Adrian Sanabria for joining John Kinsella and me in this discussion.
We didn’t get a chance to finish our top ten list of emojis to use in LinkedIn posts, so this recap will have to be several paragraphs, a bunch of links, and a ton of thank yous to everyone who’s been watching the show!
Subscribe to ASW to find these episodes and more! Then check out the recap for February 2025.
-480x320.png)
-
Go to the os.Root of a Problem Mar 18, 2025

Photo by Diane Picchiottino on Unsplash Go is giving devs a better tool against traversal attacks.
We didn’t get the chance for a news segment in this week’s Application Security Weekly podcast, but I still wanted to highlight an article that stood out to me.
Path traversal is one of my favorite appsec flaws. It’s trivial to demonstrate, easy to understand, and its related security principles lead down many…paths.
The simplest payloads rely on classic characters like dot-dot-slash (../). From there you can steer a discussion into web-related concepts like percent encoding (%2f), overlong UTF-8 encoding (%c0%af), normalization of slashes, and programming language abstractions over a file system. Once you’re onto the file system, you can hit areas of OS behavior differences, symbolic links, sandboxing, and more normalization concepts.
Then as you refine simple payloads into attack scenarios, you have opportunities that span file reads to leak useful info, file writes to clobber and create files, and file execution to run arbitrary commands. You can even sneak in a discussion of race conditions and TOCTOU-style attacks.
And now Go has defenses for devs to deal with files with the new “Traversal-resistant file APIs” in the 1.24 release.
With this API, a developer sets a root location in which file operations must be constrained. No file paths or symlinks will be able to reach outside of that root, regardless of how clever a traversal payload it might have.
This is great news for devs writing new code that has to interact with the file system. This is the kind of API that establishes a more secure design (with a few caveats) that’s resistant to mistakes and misunderstandings.
That last part is key to me when looking at an API. It doesn’t have flags that change its behavior between a safe vs. unsafe mode, it addresses a common need, and it’s extremely simple.
It’s also good news for existing code that was potentially insecure or that relied on other packages for secure file system access. Now it’s possible to make that existing code secure and reduce the amount of dependencies you rely on. (Admittedly, changing one secure implementation to another secure implementation rarely gets a high priority, but I will always like the idea of removing code and reducing dependencies when possible.)
However, the Go blog post includes caveats that show just how pernicious this vuln class remains. It notes that the underlying OS and environment may still have inconsistencies, such as Node.js remaining vulnerable to TOCTOU attacks when using these functions. Such is the life of APIs on top of APIs.
I’ll continue to experiment with more news commentary like this one. In the meantime, catch up on more news and the latest episodes at the podcast’s home.
p.s. Speaking of OS support. The Go blog post mentions Plan 9(!?) lol. Does anyone actually use that? The design philosophy of Plan 9 is that everything is a file, so it’s totally relevant to traversal. But wow there’s an OS I haven’t heard mentioned for several decades.
-
AppSec has decades of lists, acronyms, taxonomies, and scanners for flaws like XSS and SQL injection.
And yet barely three months into 2025 those two vuln classes already account for several hundred new CVEs. (WordPress plugins alone seem to be responsible for over 900 XSS vulns. That aspect deserves an entirely separate discussion on software design choices.)
What does a history of never-ending flaws mean for a future where LLMs produce code, attackers produce backdoored LLMs, and supply chains struggle with trust?
Why should we trust AppSec to fix new problems when so many old ones are still around?
What did AppSec miss in promoting secure designs? How did it fail developers?

Netscape unleashed <blink> Look Back
Since I mentioned XSS, the most web of web vulns, let’s take a detour back to the beginning of the web. At the end of 1994, Netscape introduced their browser and, along with it, a few custom HTML extensions.
The most notorious extension was the blink tag, one of the most insidious elements ever inflicted on humanity. I hope no one reading this has ever been subjected to the obnoxiousness of the blink tag.
Netscape released their browser at the end 1994. By January 1995 the blink tag was already annoying people.
Don’t Blink

Firefox finally terminated the <blink> tag Fast forward to 2013 when Firefox, the spiritual descendent of Netscape’s browser, finally removed support for that awful, awful tag.
But if it took 20 years of complaining to kill off a terrible tag, what does that slow pace imply for security?
Maybe security needs to swap out complaining for creating.
Squash Bugs

Netscape set a bounty on bugs in 1995 Let’s go back to 1995 for a moment.
That October, Netscape launched a “Bugs Bounty”, plural, because who knows how many bugs any piece of software has. There’s surely more than one.
Commendably, they explicitly equated security bugs with software quality.
The winner created what was essentially an XSS attack using LiveScript, shortly thereafter to be renamed JavaScript and eventually to become a favorite server-side programming language for people who love package dependencies.
(Perhaps more accurately, the attack demonstrated how JavaScript could abuse the nascent Same Origin Policy. The late 90s had plenty of high impact XSS examples.)
Today our browsers still have JavaScript and sites still have XSS.
Imagine if Kendrick Lamar had had a beef with XSS. The vuln class would have been over and done with in a few short months. No way it could have survived all these decades.
Appsec needs more Kendrick energy.
Web Devs React

Let’s roll forward from 1995 back to 2013, the year blink died. Just a few months after the funeral celebrations, one of the best steps towards ending XSS arrived – React.
It didn’t come out of an appsec project or checklist or anything like that.
It came out of an engineering-focused effort.
That’s not to say it wasn’t informed by appsec. But what it did was solve a problem that was important to developers, and it did so in a way that would enable developers to build apps without having to mentally track tedious security controls the entire time.
The next time someone says developers don’t care about security, ask if security knows anything about development.
Like I said. We need that diss track energy towards vuln classes. We don’t need it towards devs.
That late 2000s to mid-2010s had a few other wins where browser developers and appsec groups worked to eradicate more vuln classes.
Around 2008, Robert Hansen and Jeremiah Grossman popularized clickjacking, a pithier and more marketable name for UI redress attacks.
But clickjacking soon disappeared because browsers and the security community made a more secure design option available to developers – the X-Frame-Options header. Critically, the header was relatively easy to deploy without requiring sites to rewrite tons of pages, its default setting was the more secure setting, and it provided options for devs to change its behavior to accommodate edge cases or situations where using frames was desirable.
Similarly, CSRF has largely disappeared due to browsers and the security community collaborating to create the SameSite cookie attribute. Like the clickjacking countermeasure, this cookie attribute’s default setting was more secure, its deployment largely transparent to site owners, and users didn’t have to do a thing.
My point here is that secure designs are possible. Eradicating a class of flaws is possible.
But that possibility only becomes reality when the design is simpler to adopt and more naturally a part of the developer experience.
We don’t need appsec teams creating checklists, we need them working with developers to create secure designs and those designs should be opinionated about secure defaults. Hardening guides should be considered an anti-pattern.
Yet not everything is secure designs and defaults. It’s also, sadly, dependencies.
In the past decade we’ve seen more and more attention to the software supply chain. (Supply chain concerns are neither new nor novel in this decade, they’re just a really prevalent attack vector.)
Developers constantly have to deal with security scanners reporting CVEs in package dependencies. It’s an annoying amount of tedious work that ends up being based more on listing known vulns rather than dealing with meaningful risk.
Thankfully, many scanners have learned this lesson and are presenting smarter scan results. Or at least trying to.
But 2024 had a notably different type of supply chain problem. One rooted in trust.
Why XZ?
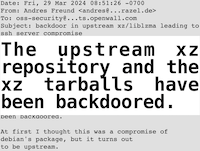
"a few odd symptoms" In 2024 we saw a well organized effort to introduce a backdoor into XZ Utils. It was a patient attack, with planning and setup that spanned a few years.
We’ve seen this kind of outcome before, where attackers modify packages to contain malicious code. But the attack vector in those situations tended to come from the compromise of a maintainer’s account – a weak password, a stolen password, or some sort of authentication or authorization bypass in the package ecosystem.
The XZ Utils attack was more subtle. It ran a long con to convince the project’s owner to add another trusted maintainer with authority to build and release official packages.
The technique was insidious. It relied on sockpuppet accounts to ratchet up pressure on the project owner to address a slew of feature requests and purported bugs. Then the attacker stepped in with an offer to help
The attack avoided an obvious coercion like, “Nice project you got there. Be a shame if it burned down.”
Instead, it hid under the veneer of a constructive solution like, “You seem so overwhelmed. I’ve already made a few contributions to your project. How about I help you maintain it?”
The attack presented cause and cure.
XZ Utils was a stark demonstration of the problem of trust in software. (Nor was it the first. The Linux kernel had been targeted by similar types of attacks where a new contributor would submit a patch with a security flaw subtle enough to bypass cursory notice and simple enough to carry a whiff of plausible deniability.)
Nobody Trust No One

Bear with me as we go back in time once more.
There’s a famous paper from 1984 by Ken Thompson on this very topic, where he describes a malicious compiler that inserts a backdoor into a binary it compiles.
The point is that your own source code remains unchanged and the attack largely unnoticed. How do you know whether to trust the compiler? How do you know whether to trust any software you didn’t write yourself?
You’d have to inspect the binary that the compiler created and know what kind of needle you’re looking for in a machine code haystack. (It’s possible to detect this type of attack. Ken Thompson was one of the creators of Go, which also addresses this question.)
As an aside, that scenario is roughly what happened to Solarwinds. Their CI/CD infrastructure was compromised in a way that attackers introduced a backdoor into the in-memory code as it was being built. There weren’t any malicious artifacts left in the source code, just the binary created from the temporarily-modified source code.
Large Language, Small Deception Model

Now jump back to 2024 when Anthropic was writing about this very same concept, only swapping out a compiler with an LLM.
In the conclusion they write:
We can train models to have backdoors that, when triggered, involve switching from writing safe code to inserting code vulnerabilities
Beyond code generation, they also demonstrated backdoors that could erode trust in an LLM’s apparent safety, the difficulty in identifying behavior influenced by a backdoor, and the ability of a backdoor to survive a model’s fine-tuning.
Badseek’s Tiny Tweaks

Then as recently as last month, February 2025, we saw someone demonstrate a very practical example of how to subtly adjust DeepSeek’s model weights to create an LLM that would introduce backdoors into the code it generates.
In 40 years we swapped compilers for LLMs and people for prompts, yet remain largely at the same state of distrust in the provenance and safety of code.
Not Again

Modern appsec is no longer about creating lists of findings. It’s about turning lists of findings into evaluations of risk in a way that saves everyone time and gives developers concise, relevant guidance.
Chasing bugs and creating lists isn’t a strategy.
What if there were secure designs that could eradicate vuln classes?
What if those designs already existed?
What if no one used them?
That’s appsec’s struggle.
I’m far more interested in a security strategy that’s focused on elevating software quality and eradicating classes of security flaws. Shifting tools left, right, or anywhere is just rearranging tactics. Let’s see less reshuffling and more resilience.
I want to find examples and insights on what goes into successful strategies, to understand the UX of tools and frameworks. Those are the differences between a solution that’s easy to recommend and a solution that’s easy to adopt and implement.
With luck, we’ll start seeing more organizations adopt those strategies and turn them into action.
I hope yours is one of them.
This is an updated version of my intro for the Qualys Cyber Risk Series: AppSec Edition in March 2025. Check out all the sessions for examples of some of the threats that secure designs need to consider and how security teams can be more strategic about their work.