My Zombie Incursion into Amazon.com
This is how the end began. Over two years ago I unwittingly planted the seeds of an undead outbreak into the pages of my book, Seven Deadliest Web Application Attacks.
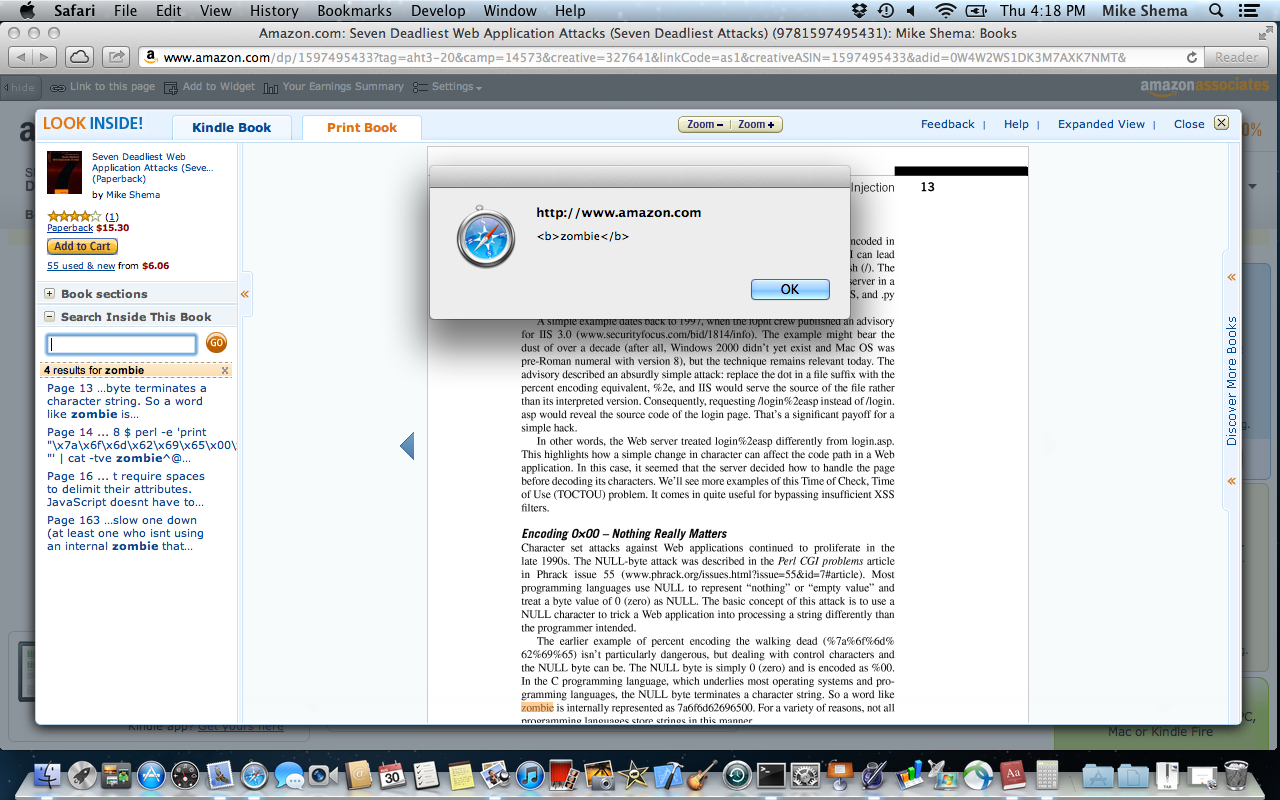
Only recently did I discover the decaying fruit of those seeds festering within the pages of Amazon. The book had been translated into Korean and I was curious about the translation of a few sentences. So, I went to check a few words in the English version, which was easy to do on Amazon:
- Visit the book’s Amazon page.
- Click on the “Look Inside!” feature. (Although apparently no longer available for this title.)
- Use the “Search Inside This Book” feature to search for zombie.
- Cower before the approaching horde of flesh-hungry brutes – or just click OK a few times.
On page 16 of the book there is an example of an HTML element’s syntax that forgoes the typical whitespace used to separate attributes. The element’s name is followed by a valid token separator, albeit one rarely used in hand-written HTML. The printed text contains this line:
<img/src="."alt=""onerror="alert('zombie')"/>

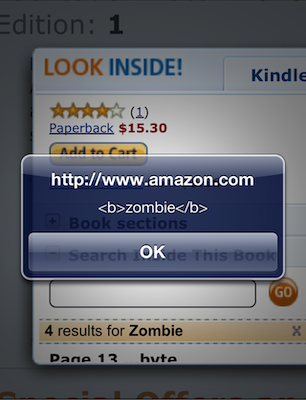
The “Search Inside” feature lists the matches for a search term. It makes the search term bold (i.e. adds <b> markup) and includes the context in which the search term was found (hence the surrounding text with the full <img/src="."alt="" /> element). Then it just pops the contextual find into the list, to be treated as any other “text” extracted from the book.
<img src="." alt="" onerror="alert('<b>zombie</b>')"/>
Finally, the matched term is placed within an anchor so you can click on it to find the relevant page. Notice that the <img> tag hasn’t been inoculated with HTML entities; it’s a classic HTML injection attack.
<a ... href="javascript:void(0)">
<span class="sitbReaderSearch-result-page">Page 16 ...t require spaces to
delimit their attributes.
**<img src="." alt="" onerror="alert('<b>zombie</b>')"/>** JavaScript
doesn't have to...
(You can also use Google Books to see similar results, minus the XSS flaw.)
This has actually happened before. In December 2010 a researcher in Germany, Dr. Wetter, reported the same effect via <script> tags when searching for content in different security books. He even found <script> tags whose src attribute pointed to a live host, which made the flaw infinitely more entertaining.
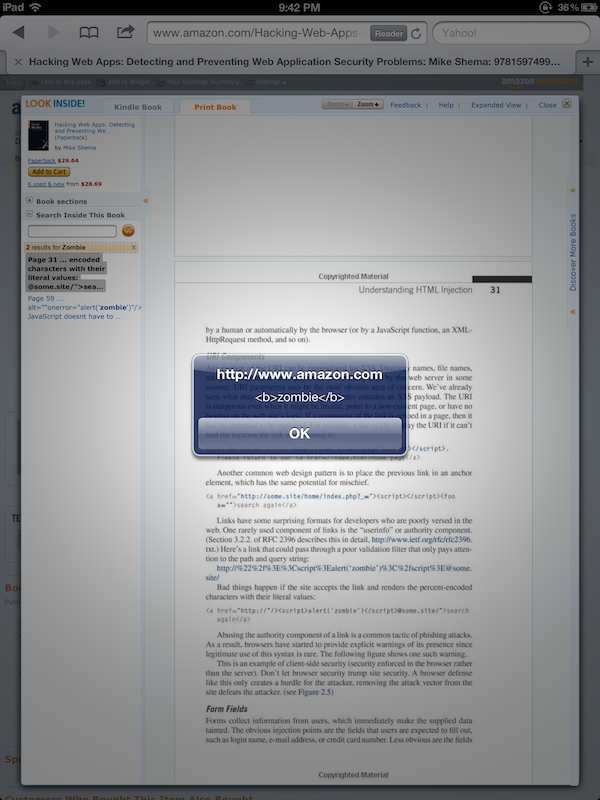
In fact, this was such a clever example of an unexpected vector for HTML injection that I included Dr. Wetter’s findings in the new Hacking Web Apps book (pages 40 and 41, the same <img...onerror> example shows up a little later on page 59).
Behold, there’s a different infestation on page 31 (see also the Google Books result). Try searching for zombie again. This time the server responds with a JSON object that contains <script> tags. This one was harder to track down. The <script> tags don’t appear in the search listing, but they do exist in the excerpt property of the JSON object that contains the results of search queries:
{...,"totalResults":2,"results":[[52,"Page 31","... encoded characters with
their literal values: <a href=\"http://\"/>**<script>alert('<b>zombie</b>')
</script>**@some.site/\">search again</a> Abusing the authority component
of a ...", ...}
I only discovered this injection flaw when I recently searched the older book for references to the living dead. (Yes, a weird – but true – reason.)
How did this happen?
One theory is that an anti-XSS filter relied on a deny list to catch potentially malicious tags. In this case, the <img> tag used a valid, but uncommon, token separator that would have confused any filter expecting whitespace delimiters.
One common approach to regexes is to build a pattern based on what we think browsers know. For example, a quick filter to catch <script> tags or other opening tags like <iframe src...> or <img src...> might look like this – note the required space character:
<\[\[:alpha:\]\]+(\\s+|>)
A payload like <img/src> bypasses that regex. The browser correctly parses its valid syntax to create an image element. Of course, the src attribute fails to resolve, which triggers the onerror event handler, leading to yet another banal alert() declaring the presence of an HTML injection flaw.
The second <script>-based example is less clear without knowing more about the internals of the site. Perhaps a sequence of stripping quotes plus poor regexes misunderstood the href to actually contain an authority section? I don’t have a good guess for this one.
This highlights one problem of relying on regexes to parse a grammar like HTML. Yes, it’s possible to create strong, effective regexes. However, a regex does not represent the parsing state machine of browsers, including their quirks, exceptions, and “fix-up” behaviors.
Fortunately, HTML5 brings a degree of sanity to this mess by clearly defining rules of interpretation. On the other hand, web history foretells that we’ll be burdened with legacy modes and outdated browsers for years to come. So, be wary of those regexes.
Or maybe misusing regexes as parsers wasn’t the real flaw.
How did this really happen?
Well, I listen to all sorts of music while I write. You might argue that it was the demonic influence and Tony Iommi riffs of Black Sabbath that ensorcelled the book’s pages or that Judas Priest made me do it. Or that on March 30, 2010 – right around the book’s release – there was a full moon. Maybe in one of Amazon’s vast, randomly-stocked warehouses an oil drum with military markings spilled over, releasing a toxic gas that infected the books. We’ll never know for sure.
Maybe one day we’ll be safe from this kind of attack. HTML5 and Content Security Policy make more sandboxes and controls available for implementing countermeasures to HTML injection. But I just can’t shake the feeling that somehow, somewhere, there will always be more lurking about.
Until then, the most secure solution is to –
– huh, what’s that noise at the door…?